国产大模型考研数学成绩大揭秘:两家破百,智力水平飞速提升!
2024年即将结束,国产大模型在这一年的智力水平提升令人瞩目。本文以2025年考研数学三试卷为测试基准,对字节豆包、阿里通义、智谱、Kimi和DeepSeek五大国产大模型的数学解题能力进行了评估。
六个月前,高考数学测试中,大模型的成绩惨不忍睹,鲜有及格。然而,随着Open AI的o1推理模型以及思维链(Chain of Thought)技术的应用,国产大模型在数理化领域的解题能力得到了显著提升。
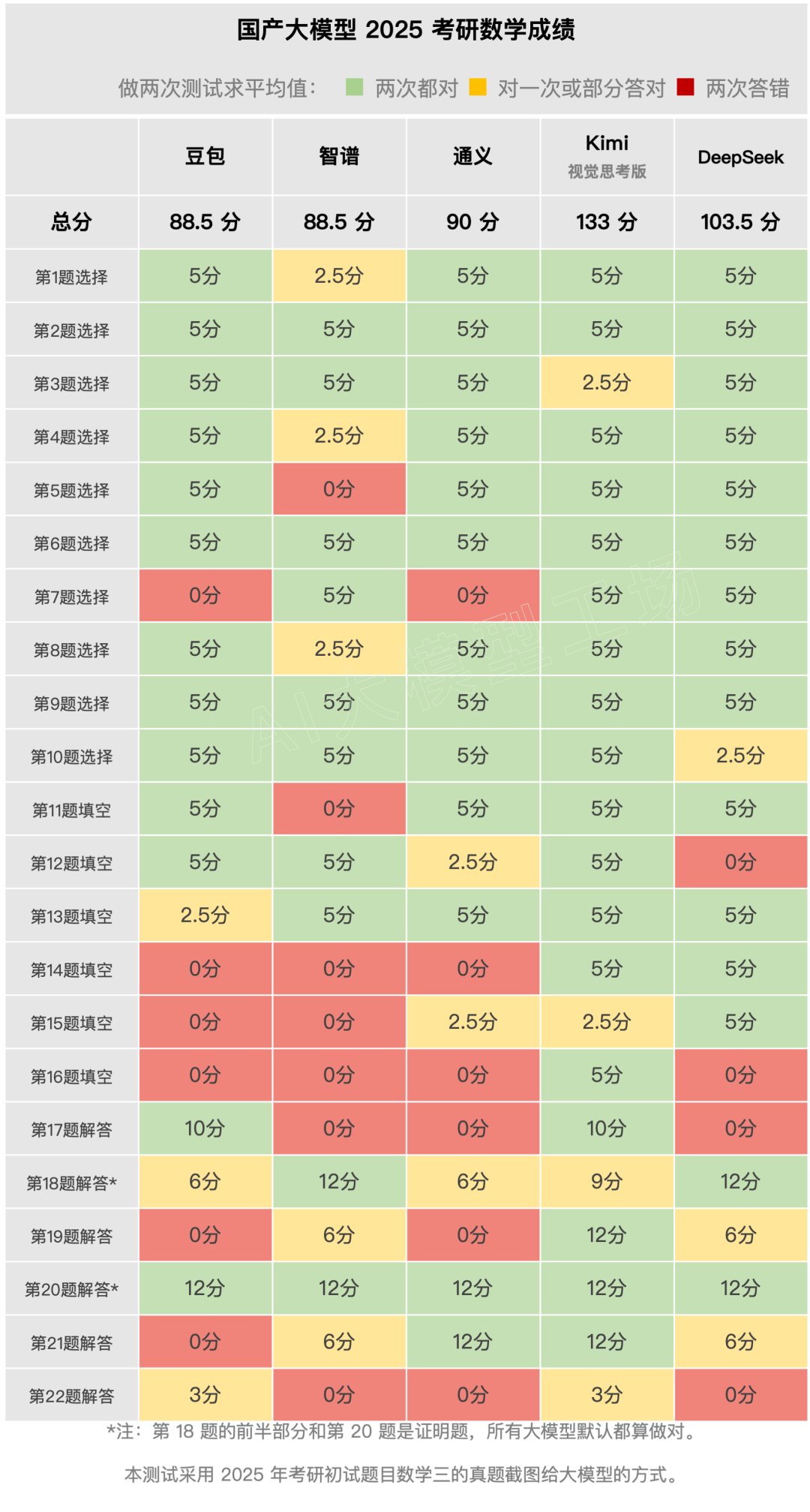
本次测试中,我们为每个模型提供了22道考研数学三试题,每题两次作答机会,取平均分作为最终成绩。测试中,我们使用了各模型的最新版本,并采用相同的图片和文字提示,以确保测试的公平性。
测试结果令人惊喜:Kimi视觉思考版以133分拔得头筹,DeepSeek紧随其后,获得103.5分。阿里通义也以90分顺利及格。字节豆包和智谱清言则分别获得88.5分,接近及格线。相比六月份的高考数学成绩,所有模型都有了显著进步,Kimi和DeepSeek的进步尤为明显。
解题风格差异:除了最终分数,解题过程也展现了不同模型的能力差异。部分模型(如Kimi视觉思考版)提供详细的推导步骤和解题思路,具有较高的参考价值;而另一些模型(如字节豆包)则仅给出简略的答案,缺乏详细的解题过程。智谱清言在部分题目上表现欠佳,出现错误或无法作答的情况。阿里通义和DeepSeek的解题步骤相对简略,但都能给出正确答案。
不同题型下的表现:在难度较低的题目中,大部分模型都能给出正确答案,但在难度较高的题目上,模型间的差距便会显现。例如,在一道定积分题目中,Kimi视觉思考版表现稳定,提供了完整的推导过程和验算;而DeepSeek则出现了无法作答或陷入死循环的情况。
总结:虽然国产大模型在解决研究生级别数学题上仍存在不足,但与几个月前相比,其逻辑思维和数理化解题能力已有了显著提升。这标志着大模型在科研等领域应用的潜力正在不断释放。未来,随着大模型能力的持续增强,它们将成为科研工作者得力的助手,并可能在推动科学进步方面发挥重要作用。












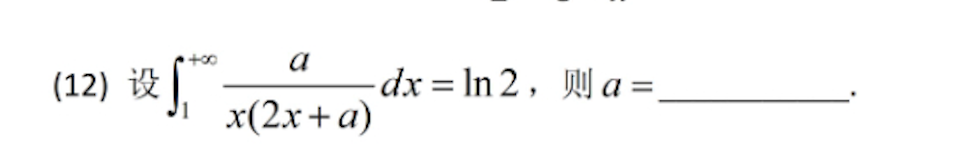





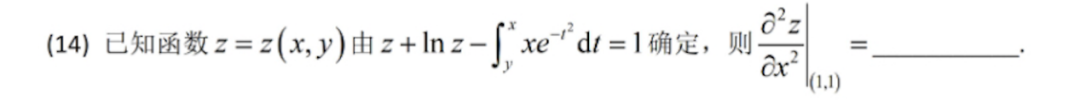


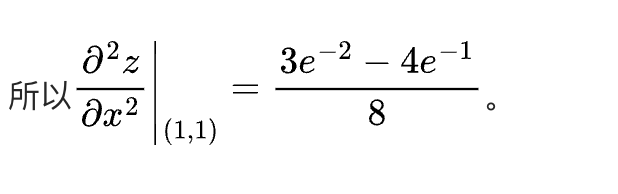




相关文章
- 详细阅读
- 详细阅读
-
《热血美职篮》评测:情怀难抵氪金,徐静雨郭艾伦也难救?详细阅读

《热血美职篮》:情怀消费还是真香体验? 蹭热度的“官方正版”,能有多正? 如今的手游市场,挂着“官方正版”头衔的游戏简直泛滥成灾。这款《热血美职篮》...
2025-05-11 319
- 详细阅读
- 详细阅读
- 详细阅读
- 详细阅读
-
同宇新材IPO疑云:高增长神话或破灭?揭秘营收、利润背离真相详细阅读

同宇新材IPO疑云:高增长神话下的重重迷雾 闯关之路:一波三折的上市征程 同宇新材,这家以电子树脂为主业的公司,其IPO之路可谓是一部跌宕起伏的连...
2025-04-20 626






发表评论




评论列表
国产大模型进步神速!看到Kimi的成绩很惊喜,这说明在解决复杂数学问题上已经取得了很大的突破。期待未来大模型在科研领域的更多应用。
国产大模型进步神速!Kimi表现亮眼,看来在科研辅助方面指日可待。期待未来有更多突破。
国产大模型进步神速!看到Kimi的成绩很惊喜,这说明在数理逻辑方面,我们已经有了和国际先进水平比肩的潜力。希望能看到更多更深入的测试和分析,期待未来大模型在科研领域的应用。